
下载与测试
YOLO (You Only Look Once) 基于深度学习框架——darknet 的目标检测开源项目。本次操作的全部过程均在 Linux 系统(Ubuntu)中完成。因为在 Windows 系统下,YOLO 源码编译的环境配置十分繁琐,容易出现问题。首先直接从 GitHub 上下载 darknet 源码:
| |
 ※ darknet 源码仓库
※ darknet 源码仓库
然后进入 darknet 文件夹中,打开 Makefile 文件。文件中最上方的三行,默认值为 0,如果你想要使用 GPU 进行运算,并开启 CUDA 加速和 OpenCV 的话,将其改为 1 即可。这里因为我仅做一个测试,数据运算量并不大所以没有开启 GPU 运算。
| |
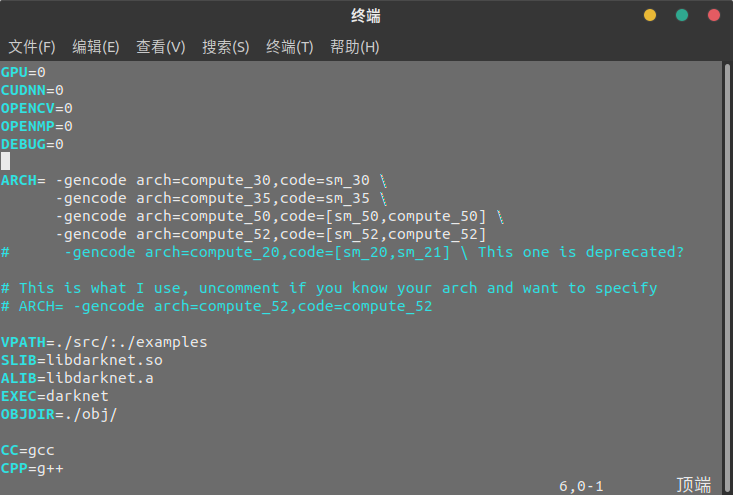 ※ Makefile 文件内容
※ Makefile 文件内容
然后执行 make 命令编译源码。编译完成后,我们从作者的网站上下载一个训练好的模型进行测试,这里有两个模型,一个名为 yolov3.weights,另一个名为 yolov3-tiny.weights,后者是一个轻量化的模型。因为我考虑后续可能会在树莓派上进行测试,所以这里我是用的是 yolov3-tiny.weights。
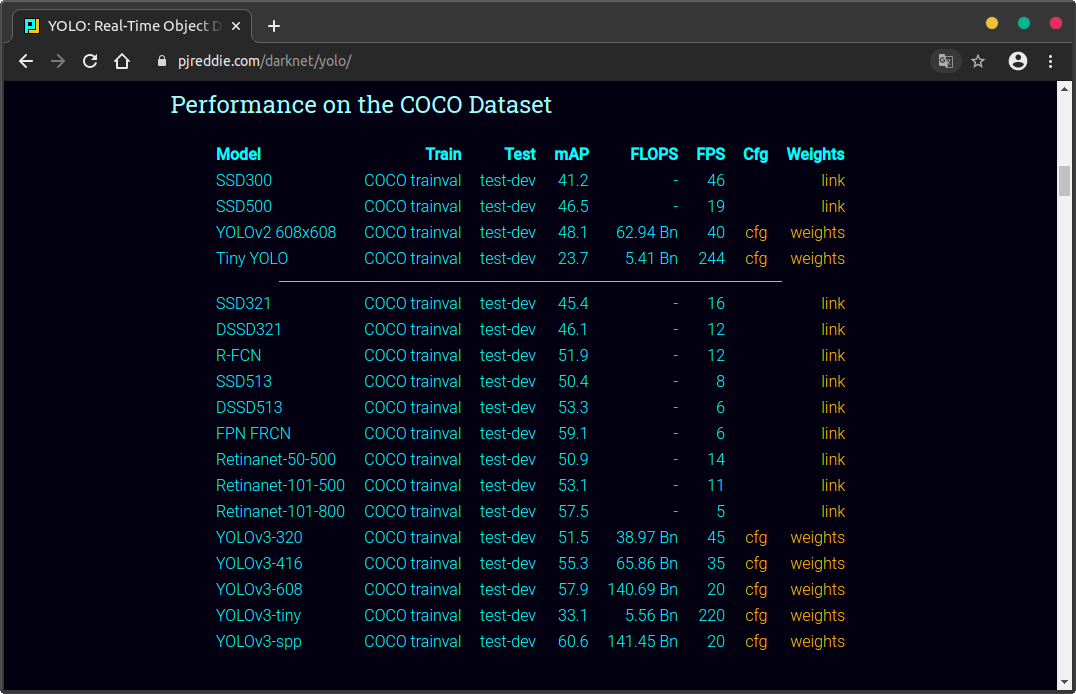 ※ 作者网站上的训练数据
※ 作者网站上的训练数据
将下载好的模型放在 darknet 文件夹下即可。我们可以在 data 文件夹下找到一些可以测试的图片,比如说 dog.jpg,执行命令:
| |
在这一条命令中,cfg/yolov3-tiny.cfg 为模型训练的相关配置文件,如果你是用的是 yolov3.weights 模型,直接替换为 cfg/yolov3.cfg即可;同样,命令中的 yolov3-tiny.weights 即为下载的模型;命令的最后一句 data/dog.jpg 为测试的图片。
执行命令后,我们可以在终端查看到图像检测的过程和结果。
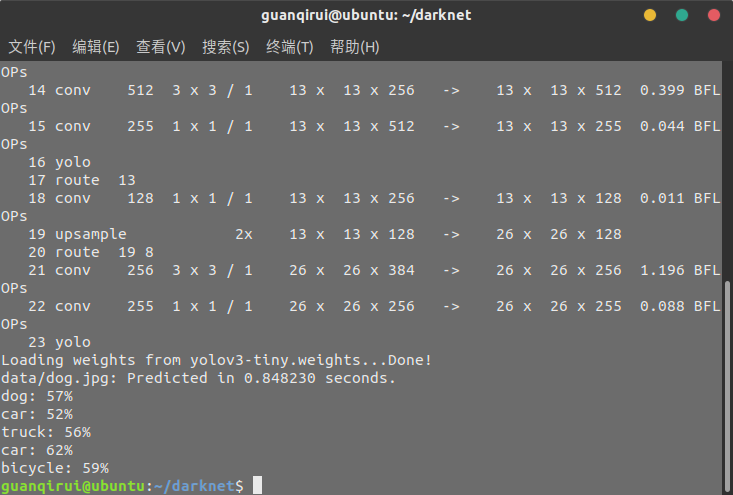 ※ 图像目标检测
※ 图像目标检测
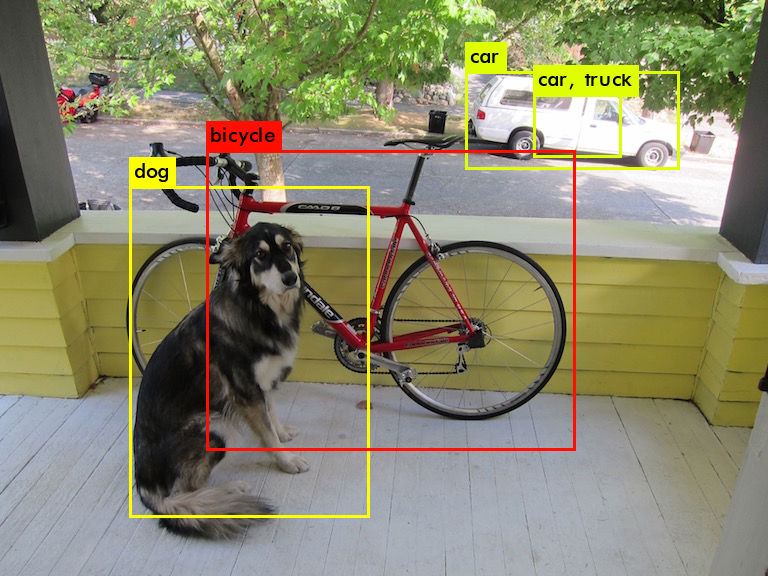 ※ 检测结果
※ 检测结果
制作数据集
因为课程项目的需要,我制作的是一个简单的垃圾分类数据集。首先我们将搜集到的图片放在同一个文件夹下,文件夹命名为 JPEGImages,将图片编号,重新命名为 000000.jpg、000001.jpg……这里我提供一个 Python 程序,直接运行即可给图片自动编号:
| |
下面进行图片的标注工作。我是用的标注工具是 LabelImg,其 GItHub 仓库地址为:https://github.com/tzutalin/labelImg。作者只提供了 Windows 端的可执行文件,在 Linux 端需要自己编译。软件的编译用到了 Python 3 与 Qt 5。依次执行以下命令安装 LabelImg:
| |
然后在 labelImg 文件夹下执行 python labelImg.py 即可运行软件。
在运行软件之前,可以先打开文件夹下的 \data\predefined_classes.txt 文件,该文件中的内容是标注所用到的标签。比如我在标注垃圾的时候,会标注 glass、metal、paper、plastic 四类,那么在该文件中依次填写名称即可。
glass
metal
paper
plastic
下面我们需要新建一个文件夹,命名为 VOC + 年份,比如 VOC2007,然后将之前编号序号的图片集文件夹复制进来。另外再新建两个文件夹,分别命名为 Annotations 和 ImageSets。前者存放我们标注好的文件,后者存放的是之后编译源码的时候用到的一些文件,在 ImageSets 文件夹下再建一个名为 Main 的文件夹。
 ※ 文件详情
※ 文件详情
然后我们运行 LabelImg,软件的左侧一栏,点击「改变存放目录」,修改存放地址为 Annotations 文件夹,接着点击「打开目录」,打开 JPEGImages 文件夹即可进行标注。标注后生成的文件类型为 xml 文件,记录了图片的所在位置和标注的横纵坐标。
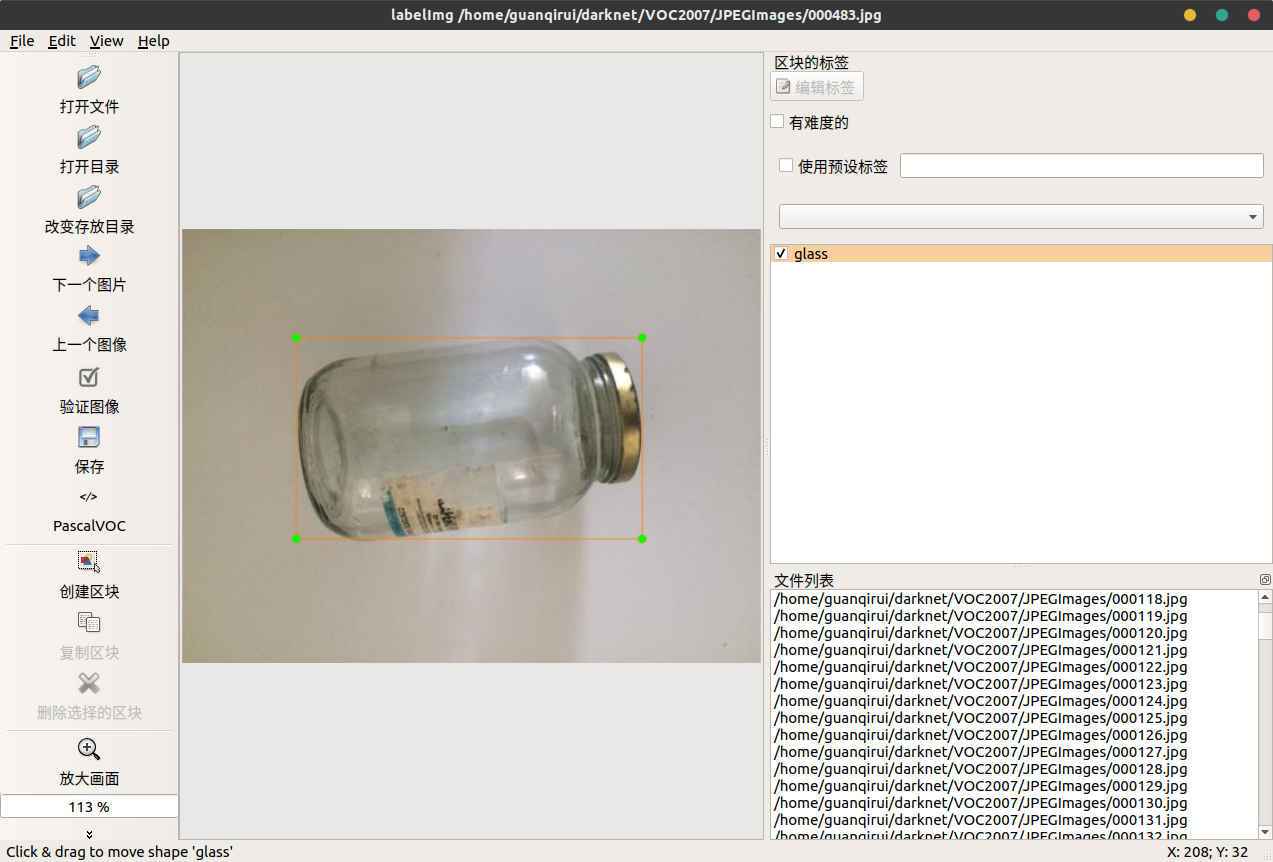 ※ 标注图片
※ 标注图片
图片标注完成后,在 VOC2007 文件夹下创建一个 Python 程序脚本,其代码如下:
| |
运行该脚本,在 ImageSets 文件夹下会生成四个文件:train.txt,val.txt,test.txt 和 trainval.txt。
源码修改
回到 darkent 文件夹,在该文件夹下新建一个名为 VOCdevkit 的文件夹,将之前制作的数据集 VOC2007 文件夹复制进来。
我们需要将数据集中的标注文件转换为 YOLO 格式的标注文件,下载作者提供的 Python 脚本至 darknet 文件夹:
| |
打开该 Python 脚本,修改其中的 sets 和 classes:
| |
其中,classes 为图片的全部种类。
运行该脚本,darknet 文件夹下会生成三个文件:2007_train.txt,2007_val.txt,2007_test.txt,VOCdevkit下的 VOC2007 也会多生成一个 labels 文件夹。然后再执行下面的命令生成最终训练用到的 train.txt 文件:
| |
下面需要对 darknet 的源码进行一些修改。打开 cfg/voc.data 文件,修改为:
classes= 4
train = /home/guanqirui/darknet/train.txt
valid = /home/guanqirui/darknet/2007_test.txt
names = data/voc.names
backup = backup
其中 classes 为图像的种类,train 和 valid 修改为相应的文件路径。
然后修改 data/voc.names 和 coco.names,内容都修改为图片的种类名称,与之前的 predefined_classes.txt 文件内容一样。接着修改 cfg/yolov3-voc.cfg,搜索文件中的关键词 yolo,总共可以找到三处:
| |
每一处都要修改两个地方:filters 和 classes。classes 为图片的种类,filters 的数值等于 3*(5+classes)。
在该文件的开头,有:
[net]
# Testing
batch=1
subdivisions=1
# Training
# batch=64
# subdivisions=16
在训练的时候,将 # Training 下的 batch 和 subdivisions 取消注释,将 # Testing 下的对应值注释掉。反之,在预测图片的时候,# Testing 下的对应值要取消注释。
训练模型
我们需要下载作者提供的预训练模型至 darknet 文件夹:
| |
执行下面的代码开始训练:
| |