在做各科练习题遇到难题的时候,经常会在搜索框中输入题干来 「百度一下」,在搜索结果中,很多答案都出自「上学吧」这个网站。
这个网站收录了非常多的题目和答案,而且正确率很不错,但这个网站设置了 IP 限制,同一个 IP 每天只能免费获取三次答案,超过三次之后就需要充值会员才可以查看答案。三次之内,点击「查看最佳答案」会弹出一个验证码窗口,验证码图片是一个简单的数学运算,将计算结果填入即可看到正确答案。超过三次之后,就需要充值会员了,对于大多数的人来说,充值会员是很不划算的。
在 CSDN 上,wjszfq 用 Python 语言写了一个脚本,通过构造随机的 X-Forwarded-For 信息来绕过 ASP 网站的 IP 检测,但是功能不是很完善。Tsing 在这个脚本的基础上进行了修改,例如对输入的网址正确性进行检查、对验证码核验不通过时的处理、修改了题目答案展示方式(不再导出 HTML 文件)、直接抓取题干内容等等。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
| import os
import random
import requests
import urllib3
urllib3.disable_warnings() # 这句和上面一句是为了忽略 https 安全验证警告,参考:https://www.cnblogs.com/ljfight/p/9577783.html
from bs4 import BeautifulSoup
from PIL import Image
def get_verifynum(session): # 网址的验证码逻辑是先去这个网址获取验证码图片,提交计算结果到另外一个网址进行验证。
r = session.get("https://www.shangxueba.com/ask/VerifyCode2.aspx", verify=False) # HTTPS 请求进行 SSL 验证或忽略 SSL 验证才能请求成功,忽略方式为 verify=False。参考:https://www.cnblogs.com/ljfight/p/9577783.html
with open('temp.png','wb+') as f:
f.write(r.content)
image = Image.open('temp.png')
image.show() # 调用系统的图片查看软件打开验证码图片,如果不能打开,可以自己找到 temp.png 打开。
verifynum = input("\n请输入验证码图片中的计算结果:")
image.close()
os.remove("temp.png")
return verifynum
def get_question(session):
r = session.get(link)
soup = BeautifulSoup(r.content, "html.parser")
description = soup.find(attrs={"name":"description"})['content'] # 抓取题干内容
return description
def get_answer(session, verifynum, dataid):
data1 = {
"Verify": verifynum,
"action": "CheckVerify",
}
session.post("https://www.shangxueba.com/ask/ajax/GetZuiJia.aspx", data=data1) # 核查验证码正确性
data2 = {
"phone":"",
"dataid": dataid,
"action": "submitVerify",
"siteid": "1001",
"Verify": verifynum,
}
r = session.post("https://www.shangxueba.com/ask/ajax/GetZuiJia.aspx", data=data2)
soup = BeautifulSoup(r.content, "html.parser")
ans = soup.find('h6')
print("\n" + '-'*45)
if(ans): # 只有验证码核查通过才会显示答案
print("\n题目:" + get_question(session))
print(ans.text)
else:
print('\n没有找到答案!请检查验证码或网址是否输入有误!\n')
print('-'*45)
if __name__ == '__main__':
s = requests.session()
while True:
s.headers.update({"X-Forwarded-For":"%d.%d.%d.%d"%(random.randint(120,125),random.randint(1,200),random.randint(1,200),random.randint(1,200))}) # 这一句是整个程序的关键,通过修改 X-Forwarded-For 信息来欺骗 ASP 站点对于 IP 的验证。
link = input("\n请输入上学吧网站上某道题目的网址,例如:https://www.shangxueba.com/ask/8952241.html\n\n请输入:").strip() # 过滤首尾的空格
if(link[0:31] != "https://www.shangxueba.com/ask/" or link[-4:] != "html"):
print("\n网址输入有误!请重新输入!\n")
continue
dataid = link.split("/")[-1].replace(r".html","") # 提取网址最后的数字部分
if(dataid.isdigit()): # 根据格式,dataid 应该全部为数字,判断字符串是否全部为数字,返回 True 或者 False
verifynum = get_verifynum(s)
get_answer(s, verifynum, dataid)
else:
print("\n网址输入有误!请重新输入!\n")
continue
|
其中 requests 和 beautifulsoup 两个库需要另外安装,建议使用 pip 方式安装:
pip install requests
pip install beautifulsoup4
首先复制上学吧某道题目的网址,格式类似以下网址:
https://www.shangxueba.com/ask/13207771.html
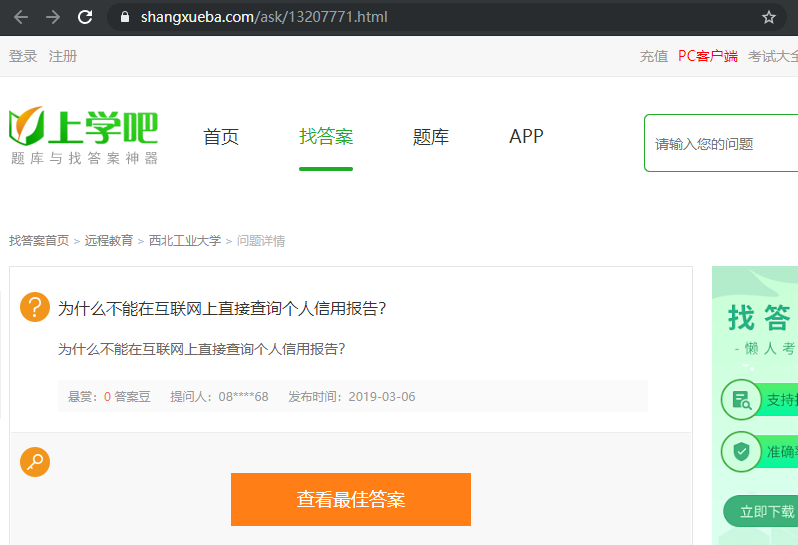 ※ 网页示例
※ 网页示例
运行 Python 脚本,将刚复制的网址粘贴进来。回车后会自动下载验证码图片存为 temp.png,然后自动读取图片并展示(实际上是生成了新的临时图片文件再打开),如果没有自动展示验证码图片,可以手动打开同目录下的 temp.png 图片查看。在命令行窗口输入验证码图片中的计算结果即可获取题目详情以及正确答案。
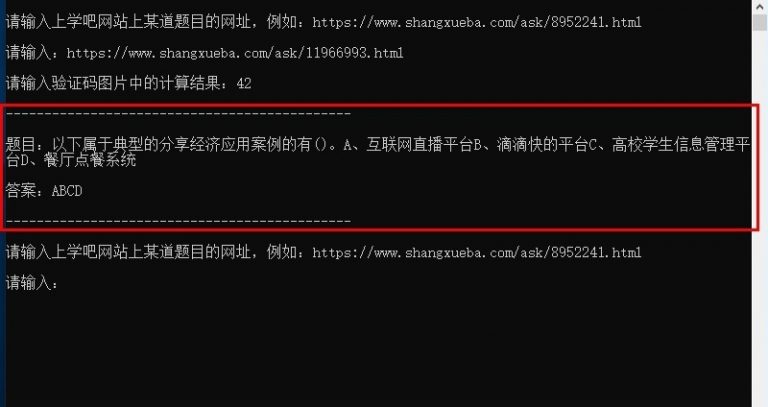 ※ 输入验证码显示答案
※ 输入验证码显示答案
在查看网页源代码的时候,发现里面有一个跳转代码,即遇到移动设备访问的时候,会自动跳转到移动端 m.shangxueba.com/ask/ 页面。
 ※ 网页源代码
※ 网页源代码
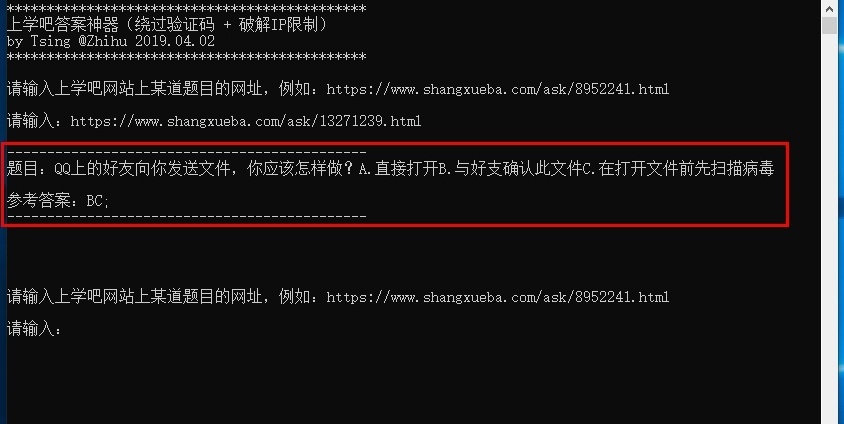
通过移动设备进入该网站后点击「查看答案」,不需要输入验证码查看,不过仍会有三次查询限制。除此之外,还有一个问题,有的题目答案中含有图片,因此之前的脚本无法在命令行窗口中显示答案。
 ※ 引用图片的答案
※ 引用图片的答案
于是,在直接删减掉验证码模块的同时,顺便解决了答案中有图片的问题,完整 Python 代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| import random
import requests
import urllib3
urllib3.disable_warnings() # 这句和上面一句是为了忽略 https 安全验证警告,参考:https://www.cnblogs.com/ljfight/p/9577783.html
from bs4 import BeautifulSoup
import webbrowser
def get_question(session, dataid):
link = "https://m.shangxueba.com/ask/" + dataid + ".html"
r = session.get(link)
soup = BeautifulSoup(r.content, "html.parser")
try:
description = soup.find(attrs={"name":"description"})['content'] # 抓取题干内容
if(description and description[0:5] != '上学吧提供'): # 页面错误的话,显示的内容是:上学吧提供考研、公务员、司法、会计、金融等各种资格考试认证学习资料,视频课程,真题,模拟试题分享下载服务和培训服务
return description
else:
return "无法获取题目内容!"
except: # 有的时候网址出错会弹JavaScript弹框:该问题不存在或未审核
return "该问题不存在或未审核!"
def get_answer(session, dataid):
data = {
"id": dataid,
"action": "showZuiJia"
}
r = session.post("https://m.shangxueba.com/ask/ask_getzuijia.aspx", data=data) # 核查验证码正确性
soup = BeautifulSoup(r.content, "html.parser")
ans = soup.select('.replyCon')
if(ans):
images = ans[0].select('img') # 有的题目答案中有图片,例如:https://www.shangxueba.com/ask/9710781.html
if(images): # 有的答案中图片出错,链接为:http://www.shangxueba.com/exam/images/onErrorImg.jpg
with open('shangxueba_answer.html','w') as f:
f.write(str(ans[0]))
f.close()
webbrowser.open('shangxueba_answer.html')
return "答案中有图片,已自动打开答案网页文件。如没有自动打开网页,可以手动打开 shangxueba_answer.html"
return ans[0].text.strip()
else:
return "答案获取失败!请检查链接是否正确。"
if __name__ == '__main__':
s = requests.session()
print("*"*45 + "\n上学吧答案神器(绕过验证码 + 破解IP限制)\nby Tsing @Zhihu 2019.04.02\n" + "*"*45)
while True:
s.headers.update({"X-Forwarded-For":"%d.%d.%d.%d"%(random.randint(120,125),random.randint(1,200),random.randint(1,200),random.randint(1,200))}) # 这一句是整个程序的关键,通过修改 X-Forwarded-For 信息来欺骗 ASP 站点对于 IP 的验证。
link = input("\n请输入上学吧网站上某道题目的网址,例如:https://www.shangxueba.com/ask/8952241.html\n\n请输入:").strip() # 过滤首尾的空格
if(link[0:31] != "https://www.shangxueba.com/ask/" or link[-4:] != "html"):
print("\n网址输入有误!请重新输入!\n")
continue
dataid = link.split("/")[-1].replace(r".html","") # 提取网址最后的数字部分
if(dataid.isdigit()): # 根据格式,dataid 应该全部为数字,判断字符串是否全部为数字,返回 True 或者 False
print('\n' + '-'*45 + '\n题目:' + get_question(s, dataid) + '\n\n' + get_answer(s, dataid) + '\n' + '-'*45)
else:
print("\n网址输入有误!请重新输入!\n")
continue
|
运行 Python 脚本,然后输入上学吧上的题目网址,直接出答案。对于答案中有图片的情况,会将答案中的图片和文字写成一个 HTML 文件,然后自动调用网页浏览器打开。
 ※ 输出答案
※ 输出答案
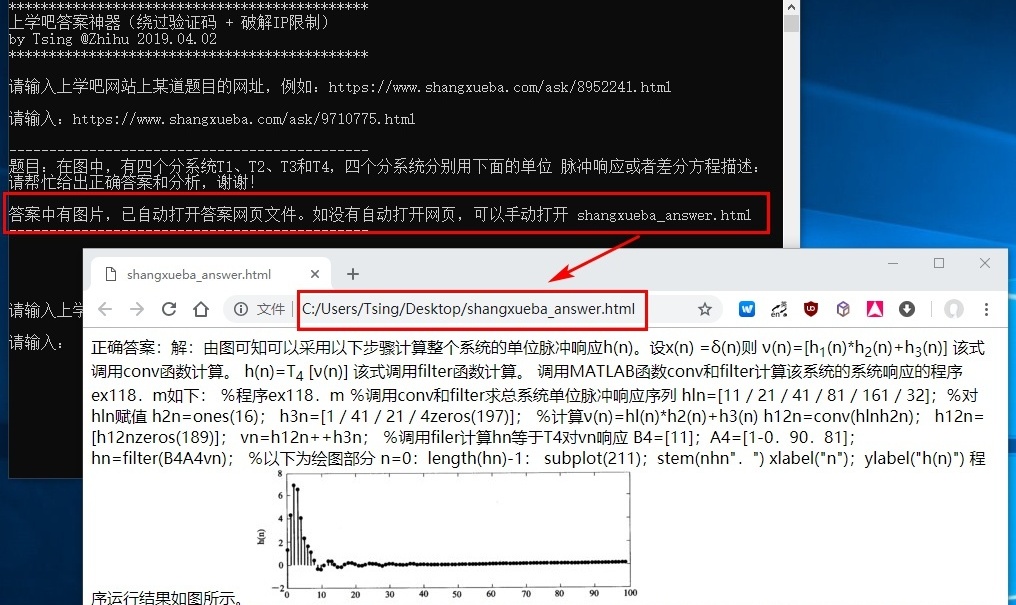 ※ 输出答案图片
※ 输出答案图片
在完成上述脚本之后,可以考虑,要是可以利用程序自动识别验证码并计算结果,效率就可以大大提高。于是,通过对验证码图片进行切图、二值化、去噪、建立模板矩阵、匹配识别等操作,可以很快识别出验证码中的数字和数学运算。
首先通过分析,所有的验证码图片都是 325 × 81 像素的,其中的数学运算只有加(+)、减(-)、乘(×)三种,两个数字的范围都是 0 到 9,且数字的位置固定不变。
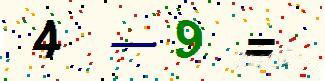 ※ 验证码
※ 验证码
这样很容易就可以切出两个数字部分
1
2
3
4
5
| def crop_image(image): # 裁切图片
cropped_image1 = image.crop((34, 20, 60, 58)) # 第一个数字的切图
cropped_image1.save("cropped_image1.png")
cropped_image2 = image.crop((176, 20, 202, 58)) # 第一个数字的切图
cropped_image2.save("cropped_image2.png")
|
可以看出切得还是不错的,而且每个数字图片的尺寸都是宽 26 像素,高 38 像素:
 ※ 切出数字
※ 切出数字
然后转成灰度图并进行二值化:
1
2
3
4
5
6
7
8
9
10
11
12
| img = Image.open(filename).convert("L") # 转成灰度图
def binarizing(img,threshold): # 遍历像素点,以一定阈值为界限,把图片变成二值图像,要么纯黑0,要么纯白255。参考:https://www.jianshu.com/p/41127bf90ca9
pixdata = img.load()
w, h = img.size
for y in range(h):
for x in range(w):
if pixdata[x, y] < threshold:
pixdata[x, y] = 0
else:
pixdata[x, y] = 255
return img
|
所谓二值化,就是遍历灰度图的像素点,以一定阈值为界限(本例中使用的是 200),使得图片的像素点要么为纯黑 0,要么为纯白 255,下图是二值化之后的图片:
 ※ 二值化处理
※ 二值化处理
然后进行噪点去除:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| def del_other_dots(img):
pixdata = img.load()
w, h = img.size
for i in range(h): # 最左列和最右列
# print(pixdata[0, i]) # 最左边一列的像素点信息
# print(pixdata[w-1, i]) # 最右边一列的像素点信息
if pixdata[0, i] == 0 and pixdata[1, i] == 255:
pixdata[0, i] = 255
if pixdata[w-1, i] == 0 and pixdata[w-2, i] == 255:
pixdata[w-1, i] = 255
for i in range(w): # 最上行和最下行
# print(pixdata[i, 0]) # 最上边一行的像素点信息
# print(pixdata[i, h-1]) # 最下边一行的像素点信息
if pixdata[i, 0] == 0 and pixdata[i, 1] == 255:
pixdata[i, 0] = 255
if pixdata[i, h-1] == 0 and pixdata[i, h-2] == 255:
pixdata[i, h-1] = 255
for y in range(1, h-1):
for x in range(1, w-1):
if pixdata[x, y] == 0: # 遍历除了四个边界之外的像素黑点
count = 0 # 统计某个黑色像素点周围九宫格中白块的数量(最多8个)
if pixdata[x+1, y+1] == 255:
count = count + 1
if pixdata[x+1, y] == 255:
count = count + 1
if pixdata[x+1, y-1] == 255:
count = count + 1
if pixdata[x, y+1] == 255:
count = count + 1
if pixdata[x, y-1] == 255:
count = count + 1
if pixdata[x-1, y+1] == 255:
count = count + 1
if pixdata[x-1, y] == 255:
count = count + 1
if pixdata[x-1, y-1] == 255:
count = count + 1
if count > 3:
print('位置:(' + str(x) + ', ' + str(y) + ')----' + str(count))
pixdata[x, y] = 255
for i in range(h): # 最左列和最右列
if pixdata[0, i] == 0 and pixdata[1, i] == 255:
pixdata[0, i] = 255
if pixdata[w-1, i] == 0 and pixdata[w-2, i] == 255:
pixdata[w-1, i] = 255
for i in range(w): # 最上行和最下行
if pixdata[i, 0] == 0 and pixdata[i, 1] == 255:
pixdata[i, 0] = 255
if pixdata[i, h-1] == 0 and pixdata[i, h-2] == 255:
pixdata[i, h-1] = 255
return img
|
所谓的噪点去除,就是删除那些孤立的点以及与主图没有交集的点。首先判断上下左右四个边界上的点,例如对于最左边一列上的黑色点,如果其右边相邻的点是白色的,那么就就是噪点,将其变为白色,其他三条边类似。对于内部的每个点而言,通过判断其周围最近的 8 个点(九宫格)中白色点的个数,如果个数大于 3,就判定为孤立点,将其变为白色。
 ※ 去躁处理
※ 去躁处理
 ※ 去躁前后对比
※ 去躁前后对比
下面,我们需要获得数字 0 到 9 的的全部图片并进行去噪点,所以需要大量的验证码图片,可以利用下面的脚本批量下载验证码图片:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| # 批量下载验证码图片
import time
import random
import requests
import urllib3
urllib3.disable_warnings()
s = requests.session()
for i in range(50):
s.headers.update({"X-Forwarded-For":"%d.%d.%d.%d"%(random.randint(120,125),random.randint(1,200),random.randint(1,200),random.randint(1,200))})
filename = 'temp' + str(i+1) + '.png'
with open(filename,'wb+') as f:
f.write(r.content)
time.sleep(1)
|
下图为下载到的 50 张验证码图片,涵盖了所有的数字。对这 50 张验证码图片进行批量切图、转灰度图、二值化、去除噪点:
 ※ 处理前后对比
※ 处理前后对比
从中挑选出噪点去除效果最好图片的作为模板,0 到 9 这 10 个数字各一个,分别遍历这几个模板图片的像素点并存为 0-1 矩阵:首先创建一个 26 列 38 行的二维数组(所有元素都为 0),遇到黑色像素点就将 0 变成 1,此处需要注意二维数组中坐标与像素点坐标是相反的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| # 验证码数字模板 0-1 矩阵的创建
from PIL import Image
num_info_list = [] # 这个数组用以存储全部数字的 0-1 矩阵
for i in range(10):
filename = str(i) + '.png'
img = Image.open(filename)
num_info = [([0] * 26) for i in range(38)] # 创建一个宽度为26,高度为38的二维数组,参考:https://www.cnblogs.com/btchenguang/archive/2012/01/30/2332479.html
pixdata = img.load()
for y in range(38):
for x in range(26):
if pixdata[x, y] == 0:
# print(x, y)
num_info[y][x] = 1 # 注意二维数组中坐标是相反的
num_info_list.append(num_info)
# for i in range(10):
# print(num_info_list[i])
f = open('1.txt','w')
f.write(str(num_info_list))
f.close()
|
下图左侧是将 5.png 转换成 0-1 矩阵的结果。然后将这个记录了所有数字矩阵信息的大数组写在程序里面作为比对模板,将需要识别的验证码图片读取所有像素点的信息,并与 10 个 0-1 矩阵进行比对,如果图片中黑色像素点出现的位置对应的矩阵点数值也是 1,就算匹配成功。然后分别记录下这张图片与 10 个矩阵的匹配数,匹配数最大的那个矩阵对应的数字就是这张验证码的识别结果。示意图如下图右侧:
 ※ 图片像素点转化为矩阵
※ 图片像素点转化为矩阵
下面是匹配识别代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| # 验证码的比对与识别
from PIL import Image
num_info_list = [[ matrix 0, matrix 1, matrix 2, matrix 3, matrix 4, matrix 5, matrix 6, matrix 7, matrix 8, matrix 9 ]]
# num_info_list[i] 就表示是数字 i 的 0-1 矩阵
# 由于文章篇幅所限,这里不再给出数字 0~9 的矩阵详细代码,这里仅用文字「matrix x」替代,完整代码参见该页脚注
img = Image.open('test.png')
count_list = [] # 记录当前图片像素信息与每一个 0-1 序列的匹配程度
pixdata = img.load()
for i in range(10):
count = 0
for y in range(38):
for x in range(26):
if pixdata[x, y] == 0 and num_info_list[i][y][x] == 1: # 图片中黑色像素点出现的位置对应的矩阵点也是 1
count = count + 1
count_list.append(count)
print(count_list)
print('当前图片的识别结果:' + str(count_list.index(max(count_list)))) # 找到匹配数最大的那个元素的序号,而序号和数字是相同的。
|
识别准确度还不错,而且识别一张图片的时间不到 3 毫秒。
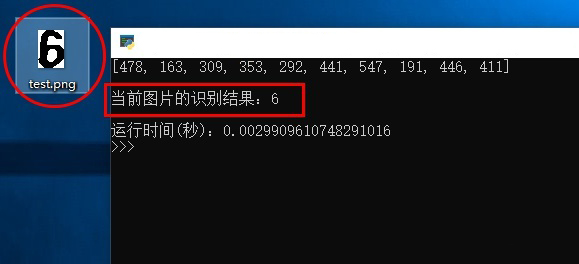 ※ 图片识别
※ 图片识别
然后进行批量识别图片,下面是 50 张验证码数字图片(已经切图并进行二值化和消除噪点):
 ※ 50 张数字图片
※ 50 张数字图片
在当前的 50 张数字图片范围内,识别准确率为 100%。
同理可以实现三种运算符的识别。为了提高效率,选定一个 20*20 像素的小区域,位置如下图所示,这样裁剪出来的图案区分度足够大。
 ※ 验证码中的运算符
※ 验证码中的运算符
进行批量切图之后同样进行二值化和去噪点,然后选出三张最好的图片作为模板建立运算符号的 0-1 矩阵。
 ※ 运算符去躁
※ 运算符去躁
利用模板矩阵,实现了运算符号识别率 100%。
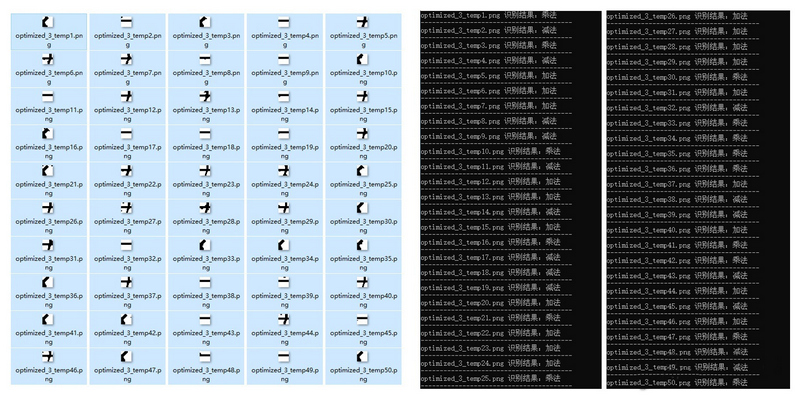 ※ 运算符识别
※ 运算符识别
基于以上成功实践,下面对整张验证码图片识别出数字和运算符号,然后输出计算结果。通过优化代码结构和删除不必要的文件读写,大大提高了程序运行效率。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| def check_num_match(img): # 检查数字的匹配程度
count_list = [] # 记录当前图片像素信息与每一个 0-1 序列的匹配程度
pixdata = img.load()
for n in range(10):
count = 0
for y in range(38):
for x in range(26):
if pixdata[x, y] == 0 and num_info_list[n][y][x] == 1: # 图片中黑色像素点出现的位置对应的矩阵点也是 1
count = count + 1
count_list.append(count)
return(str(count_list.index(max(count_list)))) # 找到匹配数最大的那个元素的序号,而序号和数字是相同的。
def check_opt_match(img): # 检查运算符号的匹配程度
count_list = [] # 记录当前图片像素信息与每一个 0-1 序列的匹配程度
pixdata = img.load()
for n in range(3):
count = 0
for y in range(20):
for x in range(20):
if pixdata[x, y] == 0 and opt_info_list[n][y][x] == 1: # 图片中黑色像素点出现的位置对应的矩阵点也是 1
count = count + 1
count_list.append(count)
n = count_list.index(max(count_list)) # 找到匹配数最大的那个元素的序号,为0则为加法,为1则为减法,为2则为乘法
if(n == 0):
return('+')
elif(n == 1):
return('-')
elif(n == 2):
return('*')
|
综合上述代码,另外还加入了多线程,一个不需要手动输入验证码的全程自动化的「上学吧答案神器」脚本就诞生了。运行速度非常快,基本在 0.6 秒左右。
 ※ 部分源代码
※ 部分源代码
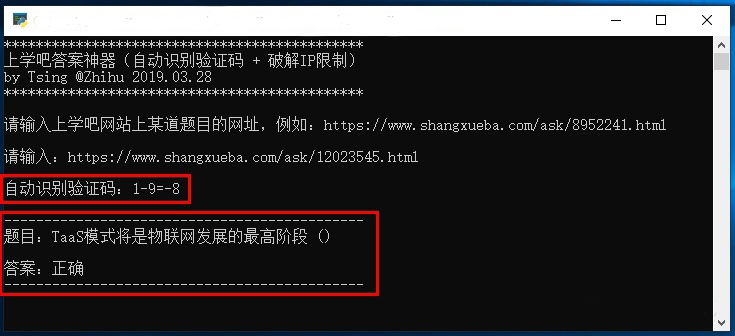 ※ 脚本运行效果
※ 脚本运行效果